距离上次写博客已经好久好久好久了,真是懈怠的生活节奏,整天混吃等死玩游戏,前些日子做毕业设计时总算又学了点新东西。学了一点深度学习和卷积神经网络的知识,附带着详细学习了一下前段时间我觉得比较有意思的图像风格转换。毕竟是初学,顺便把神经网络方面的知识也写在前面了,便于理解。若有不对的地方的话,希望指正。
主要参考的文献有 《A Neural Algorithm of Artistic Style》 和 《Perceptual Losses for Real-Time Style Transfer and Super-Resolution》 这两篇论文,以及 深度学习实践:使用Tensorflow实现快速风格迁移 等文章,代码参考了 OlavHN /fast-neural-style 和 hzy46/fast-neural-style-tensorflow 等大神的。
先说一下卷积神经网络。卷积神经网络( CNN)是一种前馈神经网络,了解机器学习中人工神经网络的话应该对这个概念不陌生。神经网络中的感知器模型如下图所示。
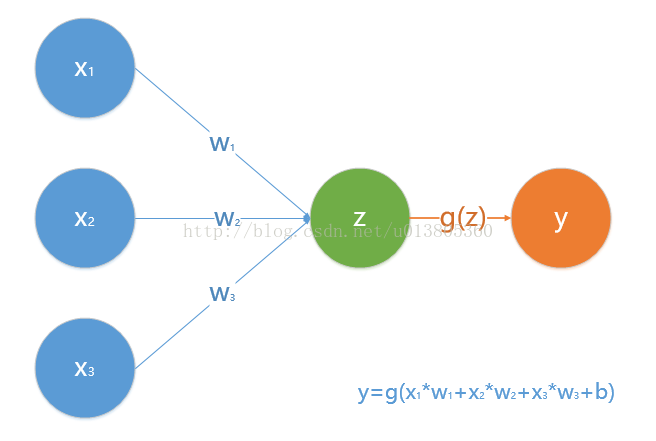
输入神经元与其各自权重相乘再相加得到z,利用激活函数g(z)进行变换得到神经元y。输入层神经元与其权重相乘再相加的过程可以用矩阵相乘相乘来表示,这点在下面的卷及神经网络里可以看到。神经网络里输入层和输出层中间的是隐藏层。
在卷积神经网络里,网络结构一般是由多个卷积层、非线性化层、池化层以及最后的全连接层组成。卷积层对输入进行卷积计算,得到的结果经过非线性化层的激活函数,再经过池化层进行采样,最后是全连接层。
先介绍卷积操作。假设输入图片是二维矩阵,每个像素值都是输入层的一个神经元,权值也用矩阵来表示,这个权值矩阵叫做卷积核,也可以成为滤波器,卷积核代表了你看这个图像时的感受野。不过卷积核是与输入图片的二维矩阵滑动计算的,这里涉及到了权值共享的问题。计算的过程如下图所示。
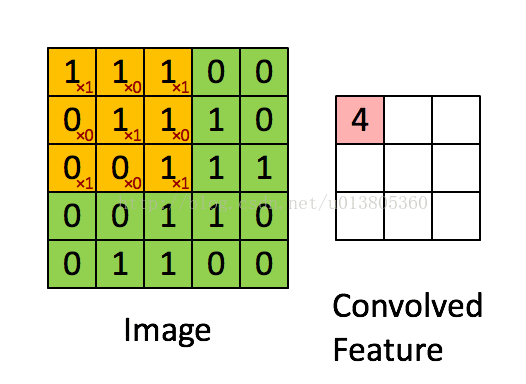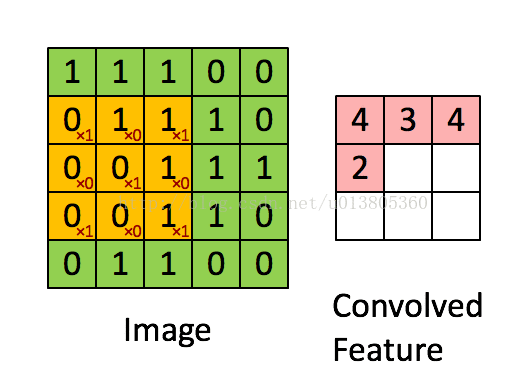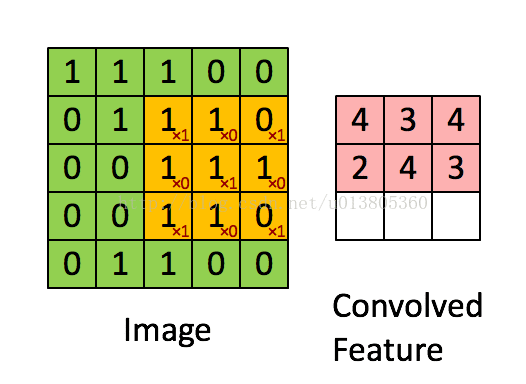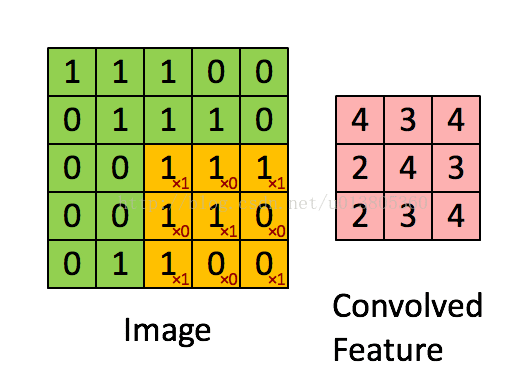
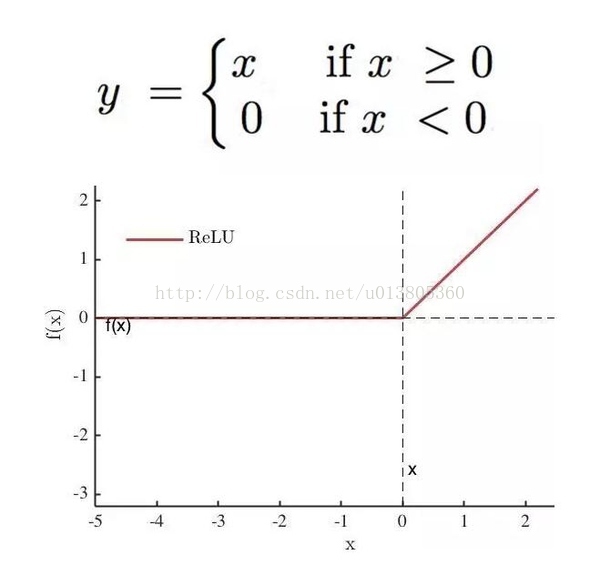
图中黄色部分为3x3卷积核,绿色的为5x5输入矩阵。卷积核在输入矩阵上滑动计算,每次都计算相应位置的乘积再相加,得到卷积后的矩阵中的新的元素。每次滑动的一格代表步长(stride)为1,也可以为其它值。然后再对右面矩阵的每一个得到的元素的值通过激励函数进行非线性化处理,一般是用的ReLU函数。如下图所示。
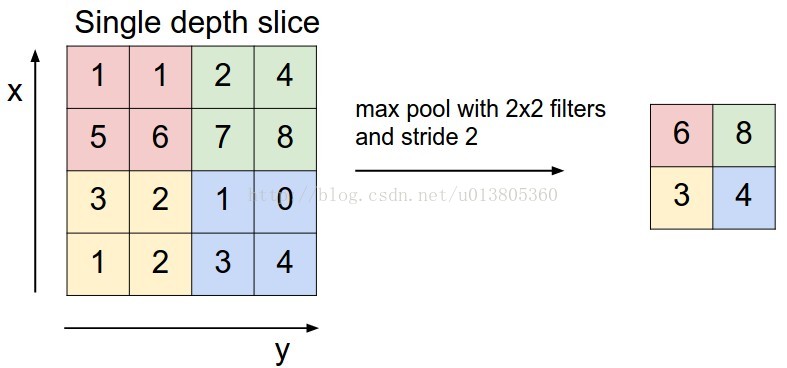
池化层进行下采样,目的是减小特征图,池化规模一般为2×2。常用的池化方法之一是最大池化(Max Pooling),即取4个点的最大值,如下图所示,非常简单。
卷积神经网络通过这样可以不断提取图像的不同层次的特征图,然后用于分类问题等等。关于卷积神经网络的详细解释可以参考 卷积神经网络全面解析 和 卷积神经网络的理解 这两篇文章,这里就不多作解释了。下面进入正题,图像风格转换的原理。
图像风格转换
以目前的深度学习技术,如果给定两张图像,完全有能力让计算机识别出图像具体内容。而图像的风格是一种很抽象的东西,人眼能够很有效地的辨别出不同画家不同流派绘画的风格,而在计算机的眼中,本质上就是一些像素,多层网络的实质其实就是找出更复杂、更内在的特性(features),所以图像的风格理论上可以通过多层网络来提取图像里面可能含有的一些有意思的特征。
根据前面第一篇论文中提出的方法, 风格迁移的速度非常慢的。在风格迁移过程中,把生成图片的过程当做一个“训练”的过程。每生成一张图片,都相当于要训练一次模型,这中间可能会迭代几百几千次。从头训练一个模型相对于执行一个已经训练好的模型来说相当费时。现在根据前面第二篇论文提出的另一种模型,使得把生成图片当做一个“执行”的过程,而不是一个“训练”的过程。
快速风格迁移的网络结构包含两个部分。一个是“ 生成网络 ”(Image Transform Net),一个是“ 损失网络 ”(Loss Network)。生成网络输入层接收一个输入图片,最终输出层输出也是一张图片(即风格转换后的结果)。模型总体分为两个阶段,训练阶段和执行阶段。模型如图所示。 其中左侧是生成网络,右侧为损失网络。
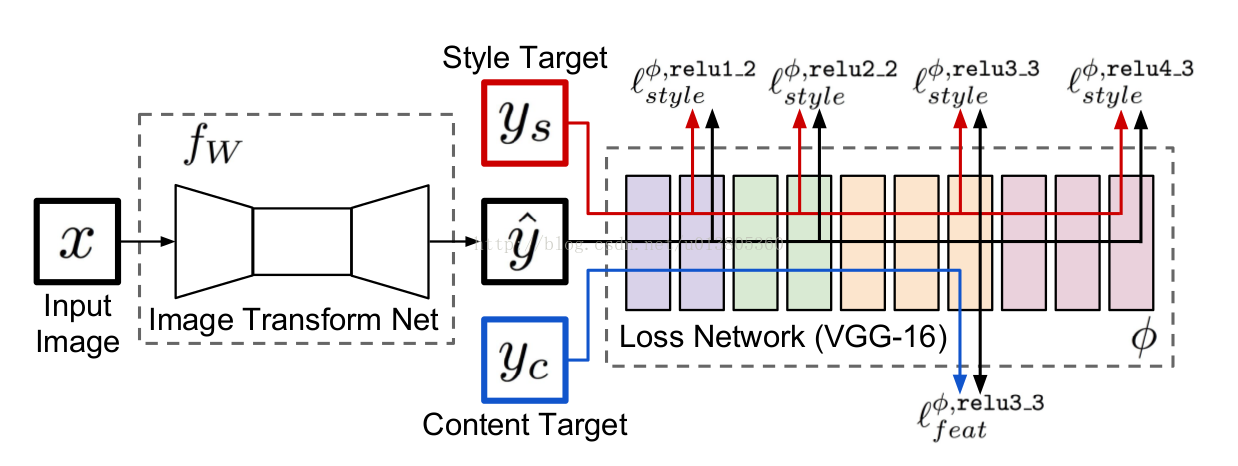
训练阶段:选定一张风格图片。训练过程中,将数据集中的图片输入网络,生成网络生成结果图片y,损失网络提取图像的特征图,将生成图片y分别与目标风格图片ys和目标输入图片(内容图片)yc做损失计算,根据损失值来调整生成网络的权值,通过最小化损失值来达到目标效果。
执行阶段:给定一张图片,将其输入已经训练好的生成网络,输出这张图片风格转换后的结果。
生成网络
对于生成网络,本质上是一个卷积神经网络,这里的生成网络是一个深度残差网络,不用任何的池化层,取而代之的是用步幅卷积或微步幅卷积做网络内的上采样或者下采样。这里的神经网络有五个残差块组成。除了最末的输出层以外,所有的非残差卷积层都跟着一个空间性的instance-normalization,和RELU的非线性层, instance-normalization 正则化是用来防止过拟合的。 最末层使用一个缩放的Tanh来确保输出图像的像素在[0,255]之间。除开第一个和最后一个层用9x9的卷积核(kernel),其他所有卷积层都用3x3的卷积核。
损失网络
损失网络φ是能定义一个内容损失(content loss)和一个风格损失(style loss),分别衡量内容和风格上的差距。对于每一张输入的图片x我们有一个内容目标yc一个风格目标ys,对于风格转换,内容目标yc是输入图像x,输出图像y,应该把风格ys结合到内容x=yc上。系统为每一个目标风格训练一个网络。
为了明确逐像素损失函数的缺点,并确保所用到的损失函数能更好的衡量图片感知及语义上的差距,需要使用一个预先训练好用于图像分类的CNN,这个CNN已经学会感知和语义信息编码,这正是图像风格转换系统的损失函数中需要做的。所以使用了一个预训练好用于图像分类的网络φ,来定义系统的损失函数。之后使用同样是深度卷积网络的损失函数来训练我们的深度卷积转换网络。
这里的损失网络虽然也是卷积神经网络(CNN),但是参数不做更新,只用来做内容损失和风格损失的计算,训练更新的是前面的生成网络的权值参数。所以从整个网络结构上来看输入图像通过生成网络得到转换的图像,然后计算对应的损失,整个网络通过最小化这个损失去不断更新前面的生成网络权值。
感知损失
对于求损失的过程,不用逐像素求差构造损失函数,转而使用感知损失函数,从预训练好的损失网络中提取高级特征。在训练的过程中,感知损失函数比逐像素损失函数更适合用来衡量图像之间的相似程度。
(1)内容损失
上面提到的论文中设计了两个感知损失函数,用来衡量两张图片之间高级的感知及语义差别。内容的损失计算用VGG计算来高级特征(内容)表示,因为VGG模型本来是用于图像分类的,所以一个训练好的VGG模型可以有效的提取图像的高级特征(内容)。计算的公式如下:
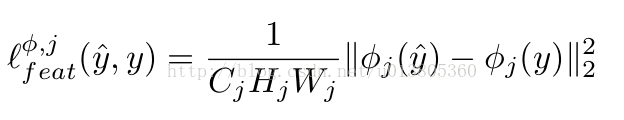
找到一个图像 y使较低的层的特征损失最小,往往能产生在视觉上和 y不太能区分的图像,如果用高层来重建,内容和全局结构会被保留,但是颜色纹理和精确的形状不复存在。用一个特征损失来训练我们的图像转换网络能让输出非常接近目标图像 y,但并不是让他们做到完全的匹配
(2)风格损失
内容损失惩罚了输出的图像(当它偏离了目标y时),所以同样的,我们也希望对输出的图像去惩罚风格上的偏离:颜色,纹理,共同的模式,等方面。为了达成这样的效果,一些研究人员等人提出了一种风格重建的损失函数:让φj(x)代表网络φ的第j层,输入是x。特征图谱的形状就是Cj x Hj x Wj、定义矩阵Gj(x)为Cj x Cj矩阵(特征矩阵)其中的元素来自于:
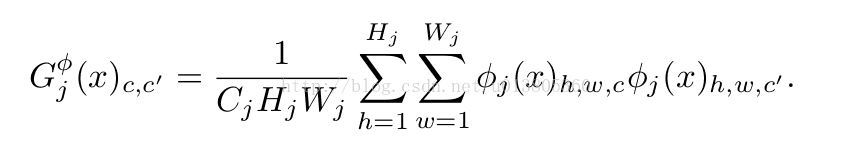
如果把φj(x)理解成一个Cj维度的特征,每个特征的尺寸是Hj x Wj,那么上式左边Gj(x)就是与Cj维的非中心的协方差成比例。每一个网格位置都可以当做一个独立的样本。这因此能抓住是哪个特征能带动其他的信息。梯度矩阵可以很高效的计算,通过调整φj(x)的形状为一个矩阵ψ,形状为Cj x HjWj,然后Gj(x)就是ψψT/CjHjWj。风格重建的损失是定义的很好的,甚至当输出和目标有不同的尺寸是,因为有了梯度矩阵,所以两者会被调整到相同的形状。
具体实现
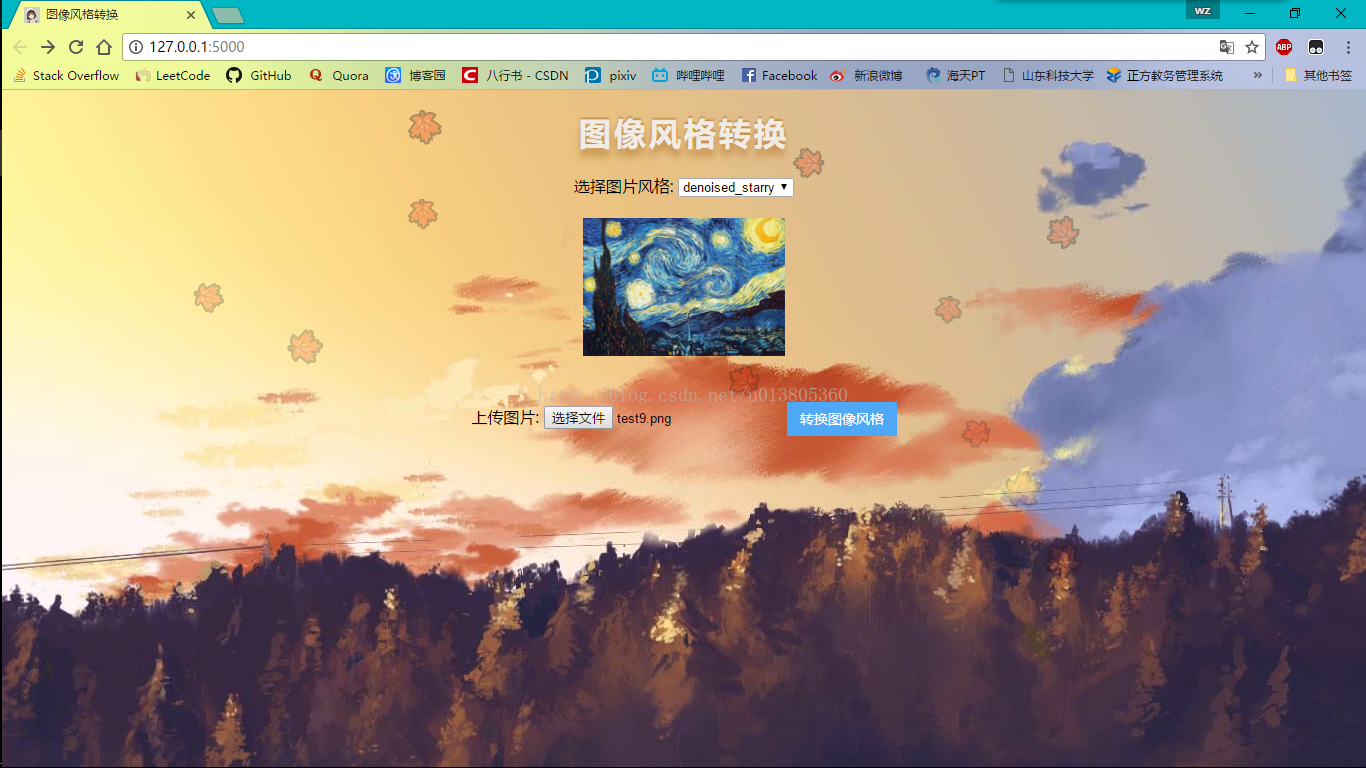
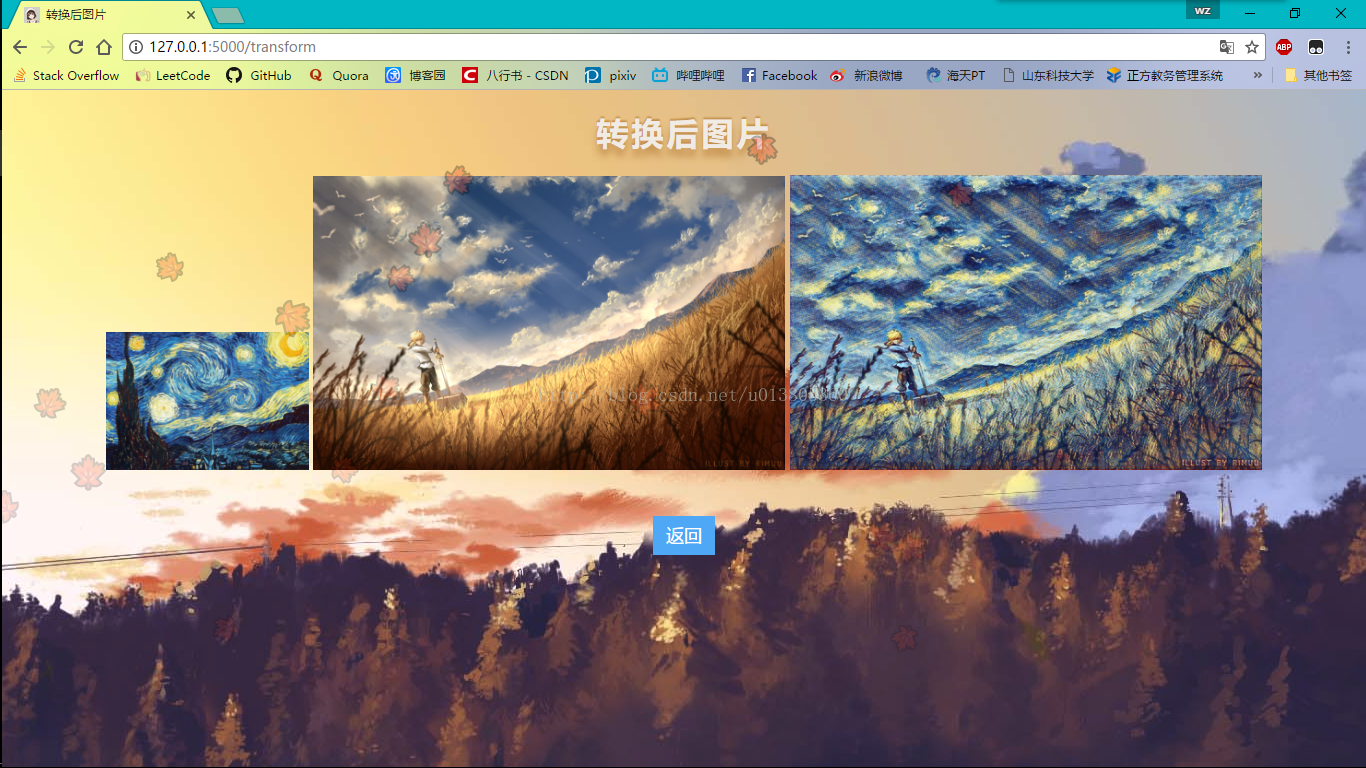
GitHub地址 mrxlz/ImageStyleTransform ,实现基本上参考了 hzy 的代码,代码从原版迁移到了python3.5,TensorFlow1.0,具体实现代码基本没变,加了一些注释,添加了一个web页面,效果如下。