概述
前段时间公司开源了内部的QMQ消息中间件,这里简单根据开源文档来看一下QMQ的实现原理,同时与kafka做一个对比.
余昭辉大佬的文章 :去哪儿网消息队列设计与实现
消息中间件的设计
一个消息中间件的设计需要考虑哪些问题呢?
- 高可用(服务与数据投递)
- 消息的存储模型
- 不同消费组消费隔离
上面是实现一个消息中间件需要考虑的基础问题,同时可以考虑的是一些其他功能:
- 事务:解决分布式事务数据一致性的问题
- 幂等Exactly once消费
- 监控
- trace
QMQ的实现
服务架构
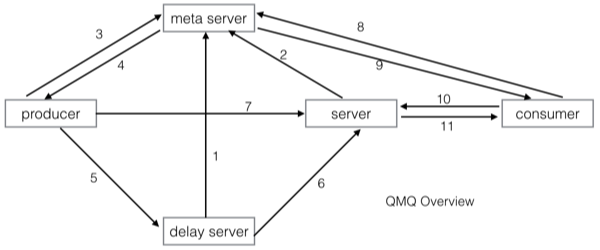
- delay server 向meta server注册
- 实时server 向meta server注册
- producer在发送消息前需要询问meta server获取server list
- meta server返回server list给producer(根据producer请求的消息类型返回不同的server list)
- producer发送延时/定时消息
- 延时时间已到,delay server将消息投递给实时server
- producer发送实时消息
- consumer需要拉取消息,在拉取之前向meta server获取server list(只会获取实时server的list)
- meta server返回server list给consumer
- consumer向实时server发起pull请求
- 实时server将消息返回给consumer
实时消息的存储
存储模型
QMQ实时消息的存储,结合了Kafka和RocketMQ的实现方式,引入了三种log:
- message log 所有subject的消息进入该log,消息的主存储
- consume log 每个主题(topic)对应一个consume log,存储的是当前主题在message log的索引信息
- pull log 每个consumer都有一个pull log,在consumer拉取消息的时候会产生log,pull log记录的是拉取的消息在consume log中的sequence
存储模型如下: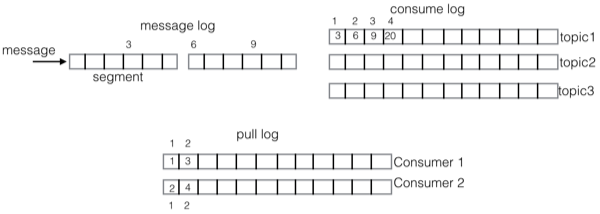
设计初衷
这里讨论的就是,为什么要使用这三种log的存储模型呢?原因如下
- 顺序append文件,提供很好的性能
- 顺序消费文件,使用offset表示消费进度,成本极低
- 将所有subject的消息合并在一起,减少parition数量,可以提供更多的subjec
- QMQ Server与Consumer解耦
最后一点,之所以说将Server与Consumer解耦,是源于kafka的存储结构和消费方式.
kafka的存储结构和消费方式,使得kafka存储消息的分区与消费者数量相关联:对于同一个topic,每个partition只能被一个Consumer Group下的一个Consumer消费
不同数量的partition和consumer可能会形成以下三种对应关系: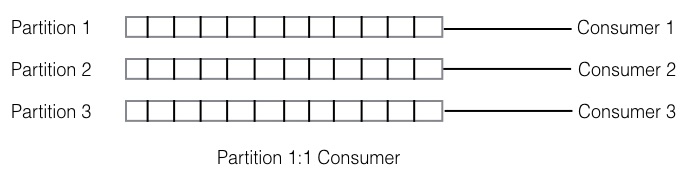
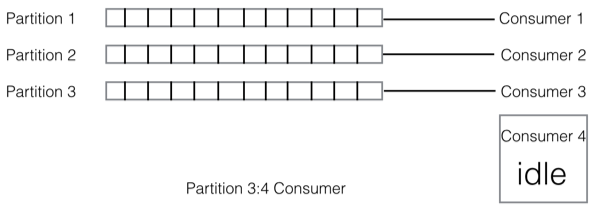
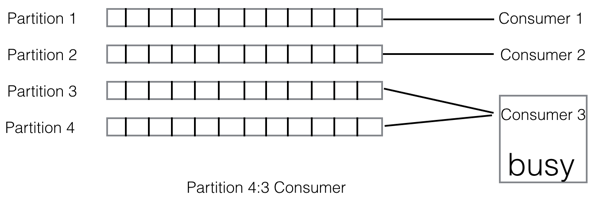
这样的关联性就导致了一个问题:当消息量突增消息产生堆积的情况下,无法通过增加partition和consumer的数量来来加快消费进度
所以对于我们的在线服务来说,存在这样一个问题是比较坑的.试问谁家的系统还没个几次突发流量啊?
因此我们可以发现,采用QMQ的三种log存储的方式,把消息中间件的存储方式与消费者解耦了,我们完全可用通过增加一个消费组下面消费者的数量,使消费者的消费能力得到线性的提升
延时消息的存储
存储模型
话不多说,看图: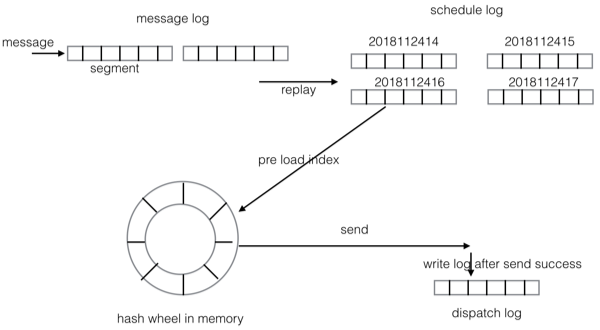
schedule log 是按小时把消息分片,不同时间段的消息存储到不同的文件中.
当消息的投递时间即将到来的时候,会将这个小时的消息索引(索引包括消息在schedule log中的offset和size)从磁盘文件加载到内存中的hash wheel上,内存中的hash wheel则是以500ms为一个刻度
消费隔离
一个主题,可以有多个消费组来消费.可以这样理解消费组和消费者:
- 每个消费组代表了一应用
- 一个应用可以有一台或多台机器作为消费者来消费消息
- 每个消费组之间的消费进度是隔离的,消费组内所有消费者的消费进度应该是共享的
由于不同消费组之间的消费进度不同,以及消费能力不同,这样在时间消费隔离的时候就面临了两个问题:
- 消费进度的隔离以消费组为维度
- 消费组消费的公平性
对于Consumer端的拉请求而言,其实就是典型的request/reponse方式,那么对于request/response的处理方式一般如下图所示: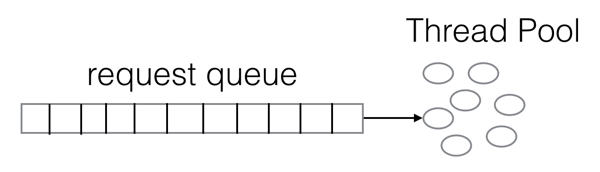
但是对于消息队列来讲有个很大的问题:比如有一个消息主题,有几个不同的消费组(consumer group)来消费,消费组里是包含多个消费者的。假设A消费组有100个消费者,而B消费组只有两个消费者,这样Server就会收到大量来自A消费组的拉请求,而来自B消费组的拉请求要少得多,最后很可能就是这种情况: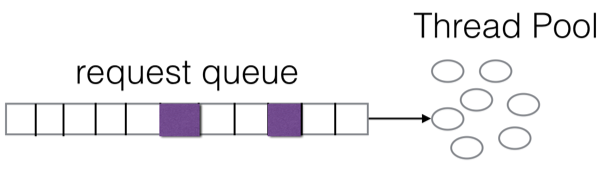
而qmq的实现方案是,为每个消费组分配一个actor,那么来自这个消费组的所有拉请求都会进入对应actor的信箱(队列),然后这些actor再被调度。
这些actor在一个线程池里被调度,当有拉请求进入对应actor的信箱时,该actor的状态变为runnable,进入线程池的队列等待被执行,当执行到该actor时,该actor的信箱里可能存在多个拉请求,那么我们并不是将该拉请求全部执行完毕,而是给每个actor分配了一个最大执行时间(时间片),如果该时间片耗完,即使它的信箱里仍然有拉请求还是会不再执行该actor,这个时候会将该actor放到线程池队列的末尾。那么就能够确保每个actor都有执行的机会,并且请求多的actor也不会挤占其他actor的资源。
高可用
分别从两个角度提供高可用能力:分片和复制
分片
首先因为QMQ不是基于partition的,所以很容易通过添加更多的机器就能提高一个subject的可用性,消息按照一定的负载均衡策略分布在不同的机器上,某台机器离线后producer将不再将消息发送给该Server。
复制
除此之外,QMQ通过主从复制来提高单机可用性。QMQ将服务端集群划分为多个group,每个group包含一个master和一个slave。消息的发送和消费全部指向master,slave只为保证可用性。
目前当master离线后,不提供自动切换功能,需要人工启动master。当slave离线后,该group不再提供接收消息服务,只提供消息消费服务。当master出现故障,导致消息丢失时,可以将其切换为slave,原来的slave切换为master,slave将从master同步数据,同步完成后提供服务。
provider发送消息
当provider消息发送给master后,slave会从master同步消息,只有消息同步到slave后master才会返回成功的响应给producer,这就保证了master和slave上都有一致的消息。当master和slave之间的延迟增大时,会标记该group为readonly状态,这个时候将不再接收消息,只提供消息消费服务。下图为消息发送和主从同步示意图: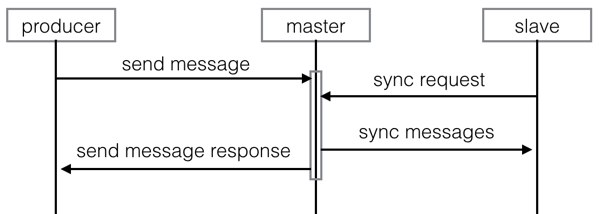
consumer消费消息
- ack机制(消费完返回ack,ack可包含异常信息)
- 重试机制(消费异常,默认每隔5s重试一次)
- 幂等Exactly once消费
服务降级
因为每个消费组都是隔离的,所以每个消费组的pull请求都在各自的队列里,那么如果前面处理慢了,就会拖慢整个队列,最后导致整个队列都是做无用功,整个系统的大量资源都被消耗了,因此就要考虑服务降级了.
服务端降级
QMQ在收到每个请求,根据请求的超时参数,都赋予了一个deadline,在该请求在actor里被执行的时候,会首先对deadline进行判断,如果觉得这个请求在deadline之前根本是无法执行完成的,那么我们就直接丢弃这个请求。那么这样就有两个作用:
- 防止队列恶化,减少无用功
- 拖慢消费者 因为请求被直接丢弃了,被丢弃的请求server端没有任何返回,那么consumer端就一直等到这个请求超时,这个时候相当于将consumer端发送拉请求的频率拖慢了,server的压力也进一步得到减轻
客户端降级
当一台Server被熔断后一段时间内拉请求(也包括发送消息的)不再发给这台Server,这样客户端也不会挂起在资源不足的server上,而server也进一步得到喘息的机会,当一段时间后客户端会用少量的请求对server进行探测,一旦server完全恢复则请求会再次在多台server之间均分。

